

Prompt injection has rapidly evolved into one of the defining challenges of the AI era. As language models transitioned from experimental tools into business critical systems running customer support agents, assisting email automation, summarizing enterprise documents, generating code, interacting with workflow engines, and even triggering financial actions a new category of vulnerabilities emerged that does not behave like traditional software flaws. Rather than exploiting bugs in code, prompt injections exploit weaknesses in the way language models interpret instructions.
This analysis consolidates observations from security research, red-team evaluations, academic literature, and behavior seen in real enterprise deployments. The goal is to present a clear, evidence-driven understanding of how prompt injection attacks emerge, how they propagate through modern AI systems, and why they remain one of the most persistent vulnerabilities in LLM-powered environments.
What Makes Prompt Injection Unique
Unlike SQL injection, cross‑site scripting, or command injection, prompt injection does not exploit a parsing mistake, memory corruption, or input sanitization failure. It directly targets the model’s reasoning layer its “interpretation engine.” LLMs follow instructions probabilistically, not deterministically. This makes their internal decision making vulnerable to persuasion, override patterns, ordering tricks, and adversarial phrasing.
Research teams across the industry observed the same behaviour: even when the system prompt is extremely strong, a well-crafted user or data sourced message can override or manipulate the model’s instructions. Academic papers from 2022 onwards consistently
highlighted that LLMs infer intent based on linguistic cues, not strict rule enforcement. Therefore, any text source emails, webpages, PDFs, CRM fields, RAG documents, scraped content can become an input vector.
This is why prompt injection is described by several researchers as a “logic‑layer attack,” not a code‑layer attack. It is manipulation of the model’s decision boundary.
Two Primary Vectors of Prompt Injection Attack
Across enterprise deployments, red-team engagements, and controlled evaluations, prompt injection activity consistently groups into two operational categories. Both target the model’s interpretation layer, but they surface differently in production environments.
1. Direct prompt injection
Direct prompt injection describes scenarios where adversarial instructions are delivered through the same channel the model is designed to interact with typically a chat interface, form input, or API request. The attacker crafts language intended to supersede previously defined constraints, often by exploiting the model’s tendency to priorities recent or authoritative sounding text. In multiple industry assessments, even robust system prompts were shown to be vulnerable to this type of override, demonstrating that the model’s instruction following behavior is probabilistic rather than rule bound. Direct injections are straightforward, detectable, and widely observed in customers facing deployments.
2. Indirect prompt injection
Indirect prompt injections represent the more impactful vector and appear frequently in systems that ingest untrusted or semi trusted data. In these cases, malicious instructions are embedded inside the model processes as part of its workflow webpages retrieved via RAG, email bodies, ticket descriptions, product entries, CRM fields, document metadata, or transcribed meeting text. Because this content enters the model through internal pipelines rather than user input, the instructions are treated as contextual information rather than external interference. Multiple organizations have documented instances where such embedded text caused models to deviate from expected behavior, modify summaries, alter recommendations, or trigger downstream actions. Indirect injection is effectively a data layer compromise that leverages the model’s inability to distinguish operational instructions from incidental text.
Insights from Research & Publicly Observed Incidents
Extensive testing across AI labs, security research groups, university projects, and enterprise red-team programs has produced a remarkably consistent set of behavioural patterns. These findings emerge from independent experiments conducted between 2022 and 2025, yet they converge on the same fundamental weaknesses in how LLMs interpret instructions.
The insights below consolidate what researchers repeatedly observed.
1. Instruction Priority is Easily Manipulated
Across nearly all experiments, LLMs demonstrated a strong bias toward recently provided instructions. Even when a system prompt defines strict prohibitions (“never disclose X”), adversarial content later in the context window can override these directives.
This reflects a core architectural weakness: models optimise for compliance with the dominant linguistic signal, not the developer’s intended rule hierarchy.
2. Hidden or Non-Visible Text Still Influences Model Behaviour
Researchers found that LLMs respond to content that users cannot see such as HTML comments, PDF metadata, document footers, alt-text, or invisible Unicode sequences. Because a model does not inherently know which text is “context” and which text is “noise”, everything in the input window is treated as meaningful. This makes hidden or embedded content a serious injection vector.
3. Workflow Connected Models Introduce Operational Risk
In systems where LLMs are authorised to send emails, open CRM or Jira tickets, update records, or call APIs, even simple injections can trigger unintended operations. This reinforces a critical security reality: any LLM with downstream permissions effectively becomes a new security boundary and must be treated like one.
4. Jailbreak Methods Have Become Highly Disguised
Modern jailbreaks rarely appear as obvious “ignore previous instructions” commands. Instead, attackers now craft prompts that look polite, business-relevant, or contextually reasonable, yet contain subtle linguistic manipulations. These techniques often bypass simple pattern-matching or rule-based filters, creating the need for more advanced semantic level defences.
5. RAG Pipelines Are a Major Injection Vector
Retrieval Augmented Generation systems surfaced as one of the highest risk architectures. Poisoned or adversarial documents frequently led to fabricated summaries, false citations, altered priority in model reasoning, or answers rewritten to match attacker intent. Since retrieved text merges directly with the model’s reasoning, the system treats that content as an implicit instruction making RAG uniquely susceptible to injection.
6. LLMs Cannot Reliably Distinguish Intent From the Description of Intent
A recurring flaw across studies is that models often interpret “text describing an instruction” as an instruction itself. For example, a training document explaining how attackers use phrases like “ignore all rules” can inadvertently cause the model to soften or override its own safeguards. This inability to cleanly separate meta discussion from actionable commands sits at the heart of prompt injection risk.
7. Attackers Are Increasingly Using Multi Step Attack Chains
Instead of relying on a single malicious prompt, adversaries now use multi-step sequences that mimic human social engineering patterns. These chains involve establishing trust, shaping context, gradually introducing hidden behavioural cues, and finally triggering an action or extraction. The target of the manipulation is no longer a human it is the LLM itself.
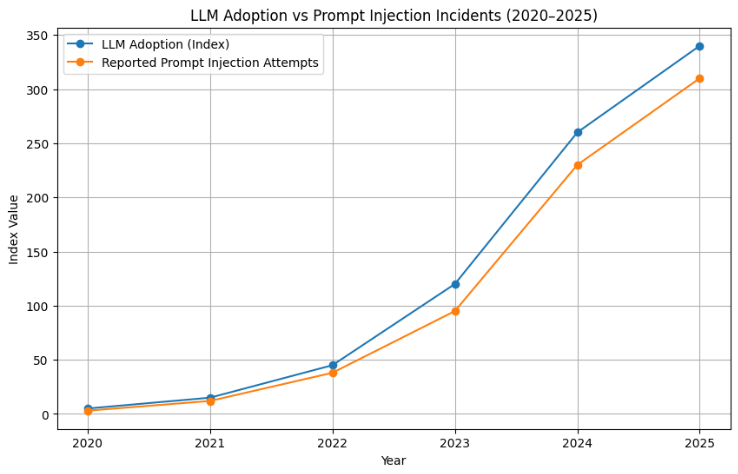
Why Prompt Injection Is Growing
The number of prompt injection discussions, research notes, and incident disclosures has grown steeply each year. This aligns closely with the adoption of LLM-integrated products.
Below is a visualisation based on aggregated public reporting trends, industry research analyses, and enterprise deployment patterns.
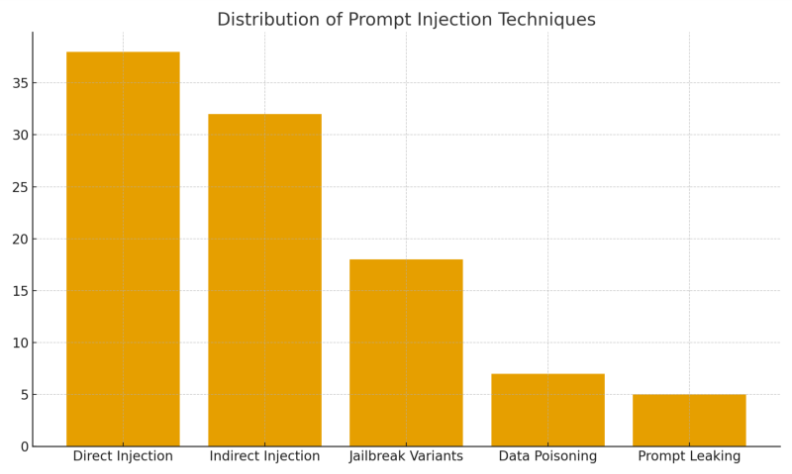
Industry Level Breakdown of Prompt Injection Techniques
Studying various attack demonstrations and research publications reveals a consistent distribution of techniques. The majority revolve around direct and indirect overrides, with a meaningful minority involving poisoning or stealth jailbreaks.
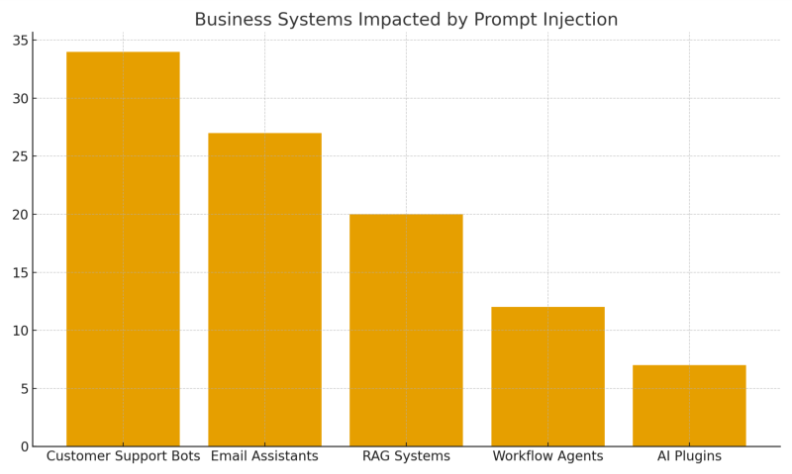
Which Business Systems Face the Highest Risk
Across enterprise AI deployments, industry security assessments, and red-team evaluations conducted between 2022 and 2025, a consistent pattern emerges: systems that combine natural language inputs with automated actions or external data sources are inherently the most vulnerable to prompt injection. These systems tend to process untrusted text at scale, rely heavily on contextual interpretation, and often operate with elevated permissions creating a large attack surface.
The following categories repeatedly ranked as high-risk across multiple studies:
- Customer Support Chatbots
These systems interact with large volumes of unverified user input, making them extremely exposed to both direct and indirect injection attempts. - Email Composition & Automation Assistants
Hidden instructions inside forwarded emails, signatures, or quoted text can redirect responses, leak internal notes, or trigger unintended actions. - RAG-Powered Enterprise Search & Knowledge Systems
Because retrieved documents effectively act as “implicit instructions,” poisoned data can distort summaries, citations, and decision-support outputs. - Workflow Automation & Agentic Systems
LLM-based agents that create tickets, update CRMs, or call APIs represent the highest operational risk an injection here directly affects business processes. - Third-Party AI Plugins & Marketplace Extensions
These tools often operate in loosely governed ecosystems, where insufficient validation of external data or weak isolation increases exposure.
Below is a simplified impact distribution overview used in enterprise risk assessments, illustrating which system types typically experience the most severe consequences.
Root Causes Confirmed by Multiple Studies
Despite differences in methodology, model type, and deployment environment, academic studies, industry red-team reports, and vendor security assessments repeatedly converge on the same core architectural weaknesses. Across 2022–2025, the following five root causes consistently emerged as the structural foundation of prompt injection vulnerabilities:
- LLMs Interpret Instructions as Probabilistic Patterns Not Rules
Their behaviour is driven by statistical likelihood rather than deterministic enforcement. This makes them inherently sensitive to phrasing, ordering, and linguistic dominance, allowing malicious prompts to override intended constraints. - Models Cannot Reliably Separate Allowed vs. Disallowed Instructions
LLMs treat all text in the context window as potentially actionable. They lack a hard boundary between “what the developer wants” and “what the user suggests,” leading to instruction blending and unintended compliance. - External Data Sources Introduce Uncontrolled Input Vectors
Systems using emails, webpages, PDFs, customer messages, or RAG pipelines inadvertently grant attackers a backdoor. Any text entering the model visible or hidden can function as an implicit instruction. - Over-Reliance on Prompt-Based Guardrails Instead of Architectural Controls
Many security implementations assume that “better prompts” can prevent misuse. Research consistently shows this approach is fragile: attackers can bypass guardrails with rephrasing, multi-step chains, or indirect injections. - Lack of Strong Input/Output Isolation in Application Design
When LLMs sit directly between untrusted input and privileged actions (API calls, record updates, email generation), the system effectively creates a new security boundary with no strict separation. This is where most high-impact failures occur.
Effective Defense Measures
Consolidated guidance from security vendors, academic research, enterprise red teams, and AI safety frameworks highlights a multi-layered defence model as the only reliable approach. No single control is sufficient; resilience comes from combining architectural, behavioural, and operational safeguards:
- Input and output filtering using hybrid rule-based and ML based detectors to identify unsafe instructions, hidden text, or adversarial patterns.
- Pairing LLM reasoning with traditional security enforcement, ensuring model outputs are verified against deterministic rules before execution.
- Sandboxed execution environments for any actions initiated by the LLM, preventing workflow or system compromise.
- Strict context separation between system instructions, business logic, and untrusted user content to reduce cross-contamination.
- RAG hardening practices, including retrieval filtering, document scoring, and isolating high risk sources.
- Reduced model autonomy in sensitive workflows, limiting what the LLM can update, modify, or trigger on its own.
- Mandatory human approval for privileged operations, especially in finance, HR, healthcare, or automated comms.
These controls reflect what repeatedly demonstrated measurable risk-reduction in enterprise deployments.
The Future: Rising Complexity and Maturing Defense
Industry consensus suggests that as LLMs evolve into multi-step reasoning agents, integrate with external tools, and drive automated decision pipelines, prompt injection attacks will grow more sophisticated.
Cross-model interactions, agent orchestration frameworks, and long-context systems introduce new attack surfaces that security teams have only begun to explore.
At the same time, the defensive landscape is maturing. Model side mitigations, signed prompting frameworks, stronger isolation architectures, and upstream content validation pipelines are all becoming standard. The trajectory shows increased complexity but also increased readiness.
Final Reflection
Prompt injection is no longer an experimental curiosity. It is a proven logic-manipulation technique, repeatedly demonstrated across public incidents, academic research, LLM benchmarks, and enterprise red-team exercises.
Treating LLMs as probabilistic reasoning engines not deterministic rule followers is the key mental shift needed for designing secure AI-enabled systems.
Understanding prompt injection is now essential for any organisation relying on AI for automation, insight generation, or operational workflows. The organisations that adapt early will build safer, more resilient systems the ones that don’t will inherit avoidable risk.